CORRECTIVE ACTIONS PLANNING. Risk Diagram (PDPC)
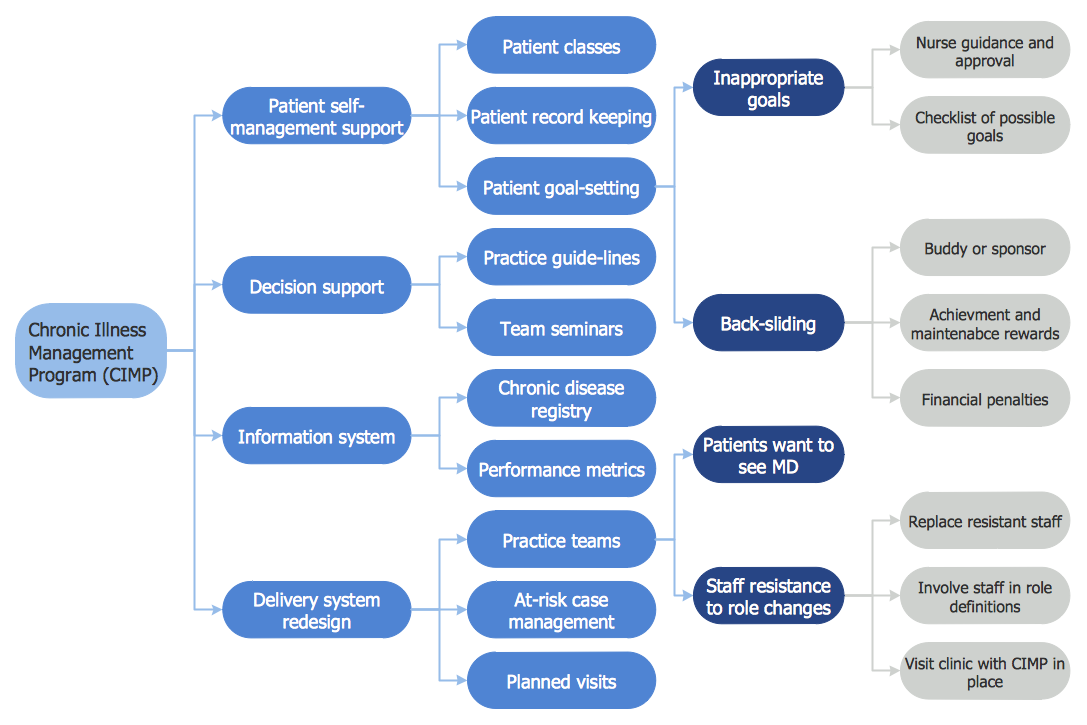

PROBLEM ANALYSIS. Root Cause Analysis Tree Diagram
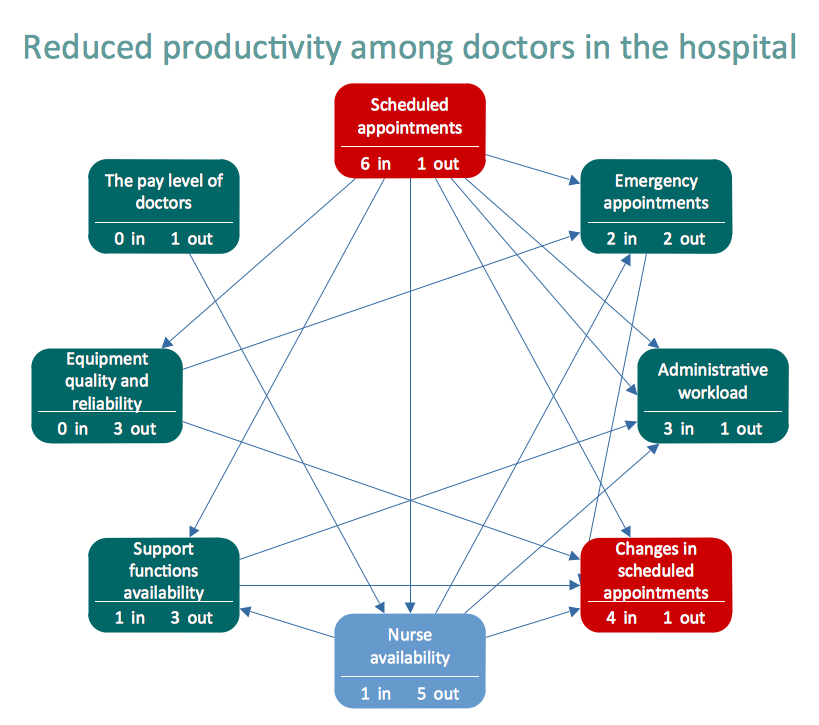
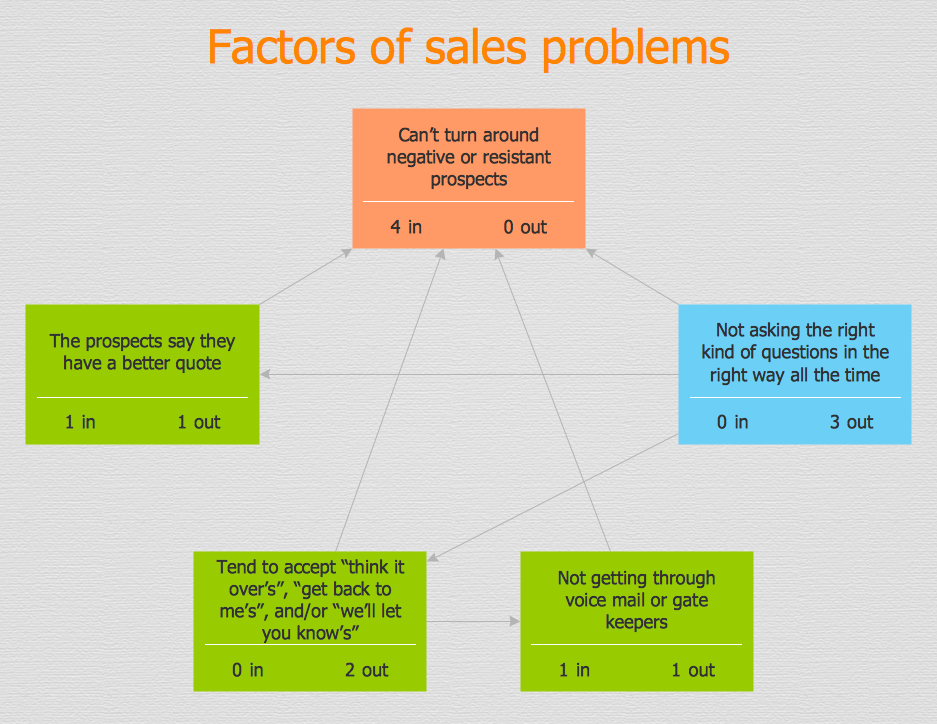
Relationships Analysis
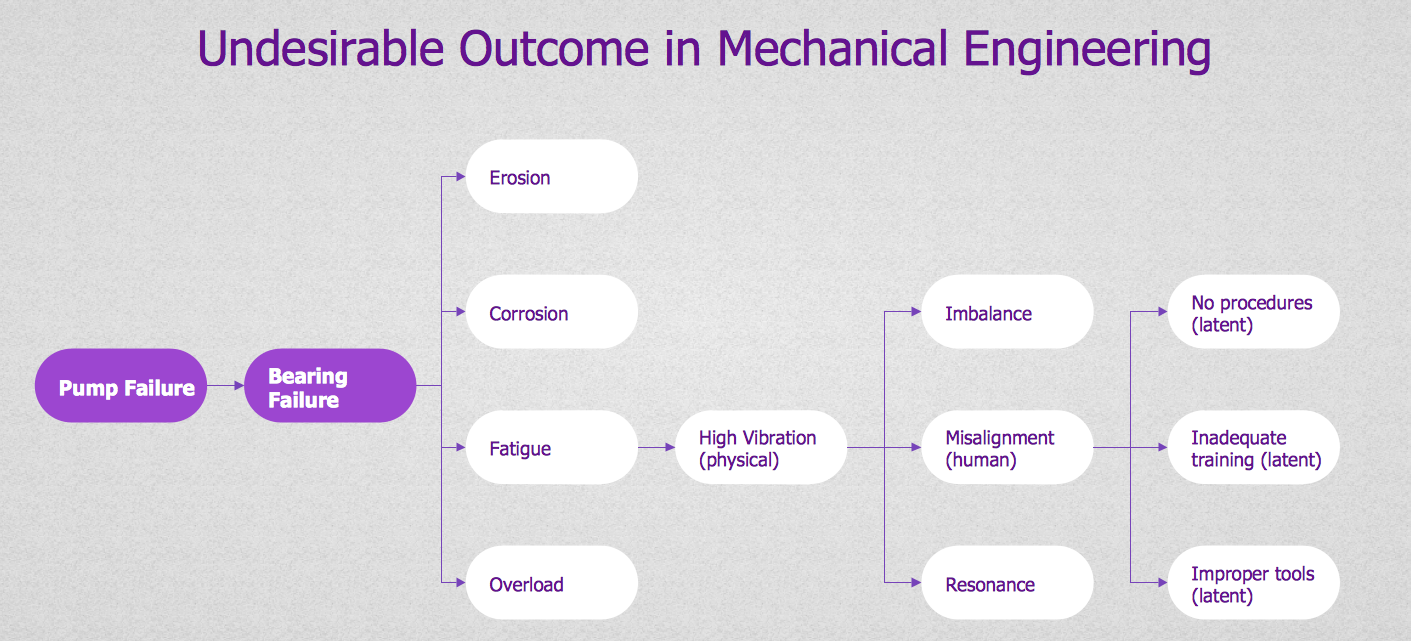
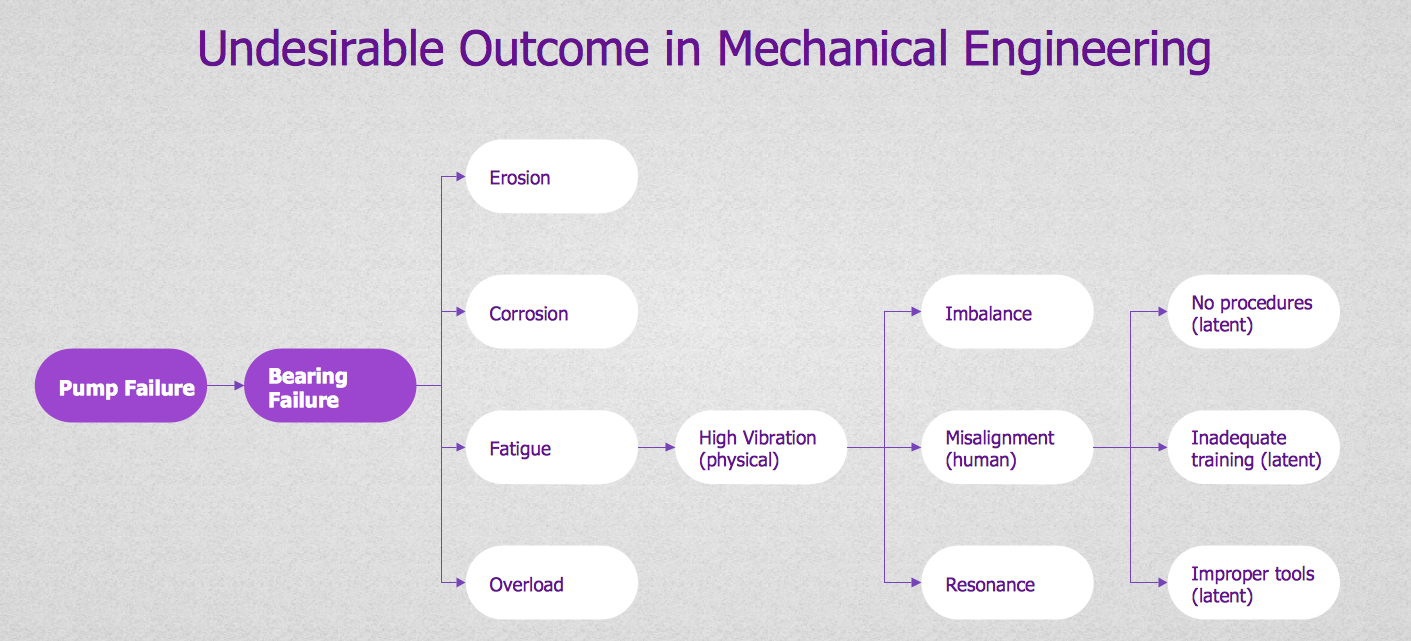
Root Cause Tree Diagram

 Seven Management and Planning Tools
Seven Management and Planning Tools
Seven Management and Planning Tools solution extends ConceptDraw DIAGRAM and ConceptDraw MINDMAP with features, templates, samples and libraries of vector stencils for drawing management mind maps and diagrams.
Decision Making
PROBLEM ANALYSIS. Relations Diagram
CORRECTIVE ACTIONS PLANNING. PERT Chart
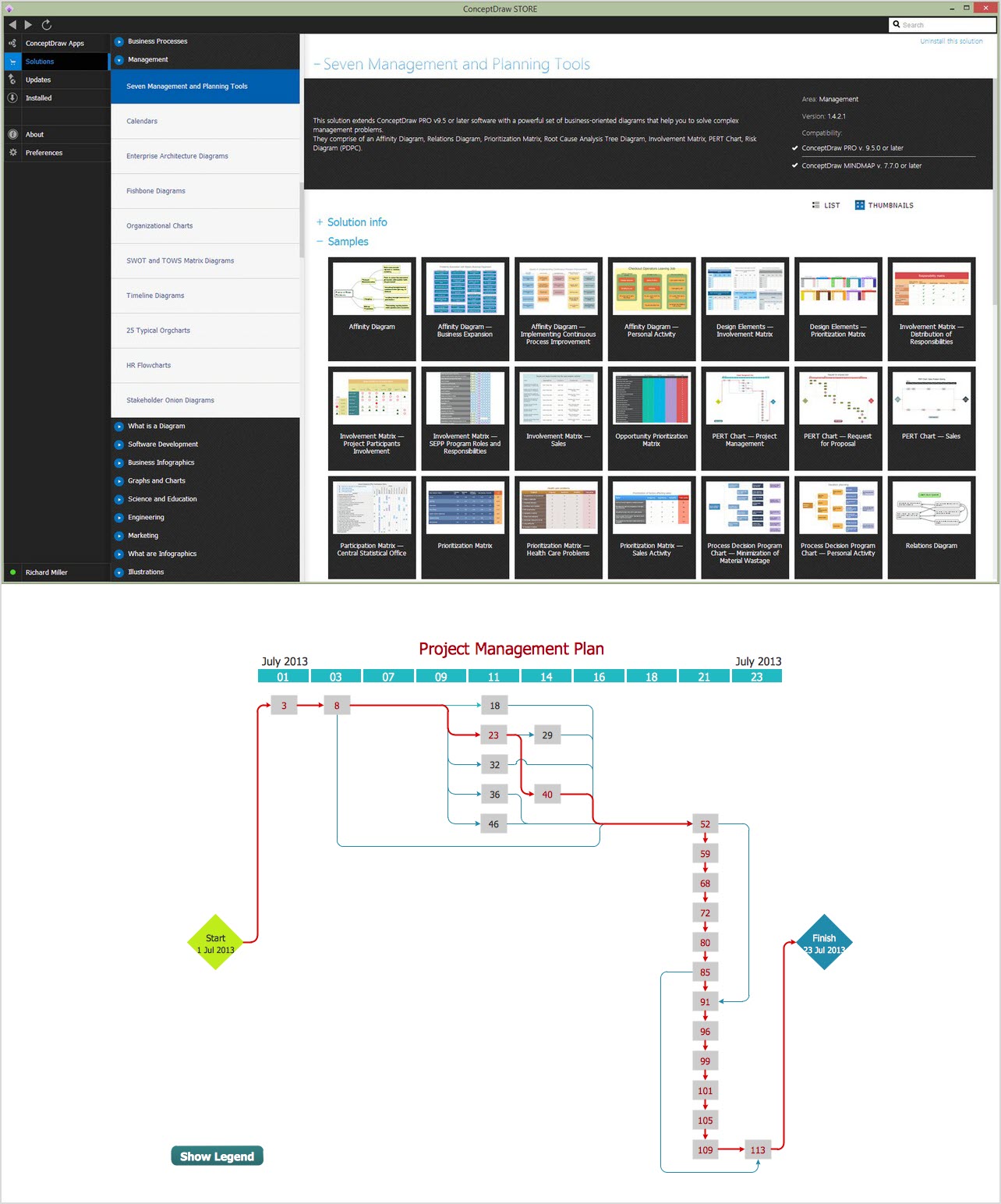
 Seven Management and Planning Tools
Seven Management and Planning Tools
Seven Management and Planning Tools solution extends ConceptDraw DIAGRAM and ConceptDraw MINDMAP with features, templates, samples and libraries of vector stencils for drawing management mind maps and diagrams.
 Fault Tree Analysis Diagrams
Fault Tree Analysis Diagrams
This solution extends ConceptDraw DIAGRAM.5 or later with templates, fault tree analysis example, samples and a library of vector design elements for drawing FTA diagrams (or negative analytical trees), cause and effect diagrams and fault tree diagrams.
Flowchart Examples and Templates

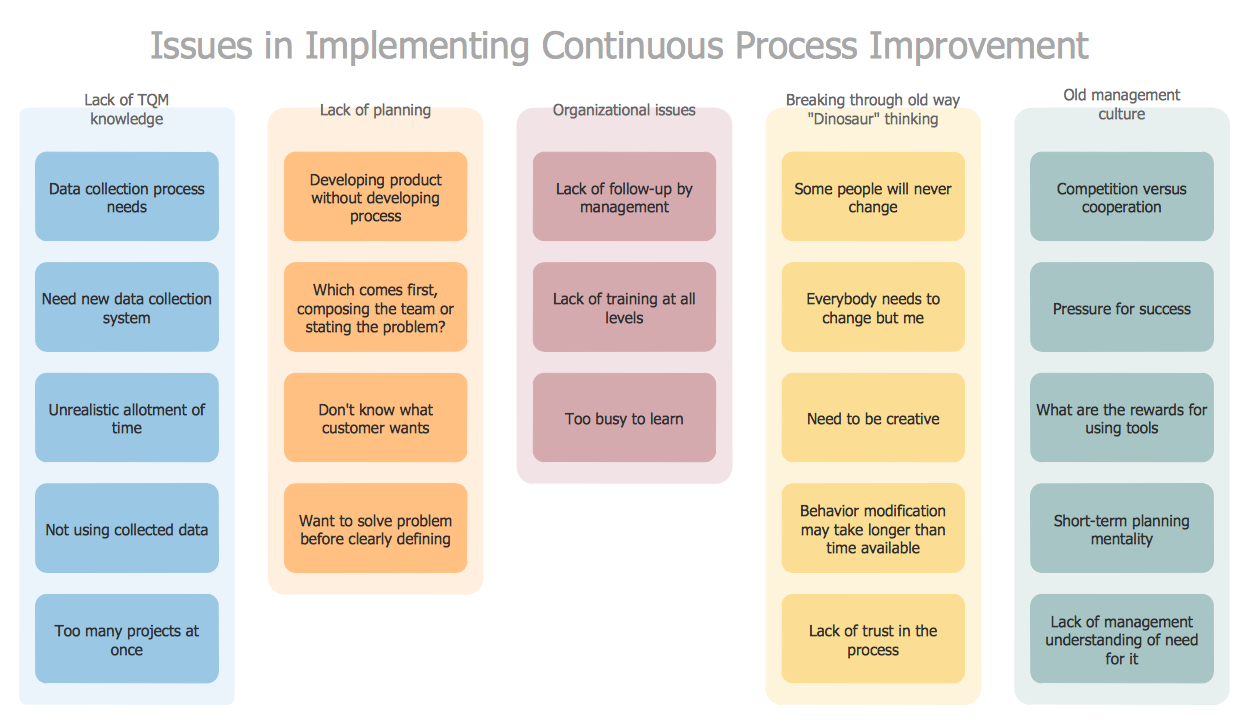
PROBLEM ANALYSIS. Identify and Structure Factors
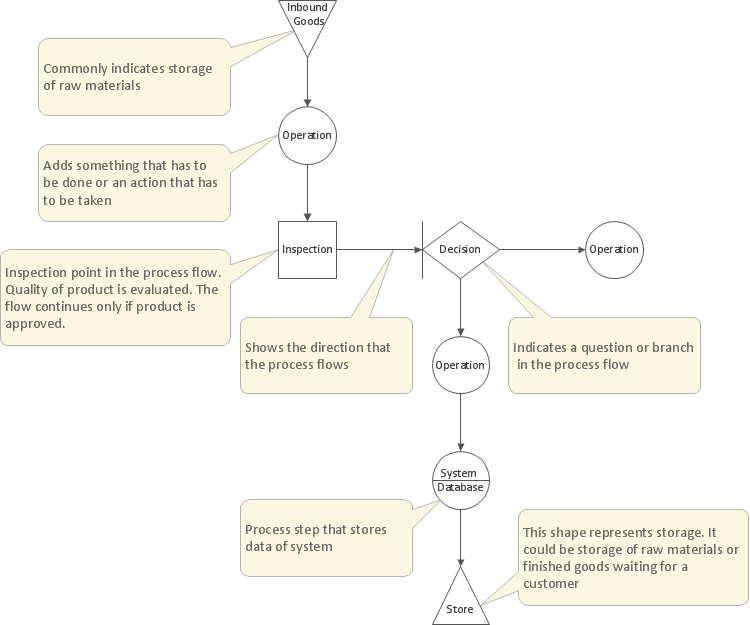
Management Tools — Total Quality Management
 Health Food
Health Food
The Health Food solution contains the set of professionally designed samples and large collection of vector graphic libraries of healthy foods symbols of fruits, vegetables, herbs, nuts, beans, seafood, meat, dairy foods, drinks, which give powerful possi
Corrective Action Planning
- Tree Diagram On Health Management
- Tree Diagram Mind Mapping Health Management
- Tree Diagram Of Healthy Food
- Helth Management Tree Diagram
- Fishbone Diagrams | Fault Tree Analysis Diagrams | Health Food ...
- Example Swot Analysis Healthcare Products
- Tree Diagram Of Health Management
- Health Food | Sequence Diagram for Cloud Computing | Fault Tree ...
- PROBLEM ANALYSIS. Root Cause Analysis Tree Diagram | Seven ...
- Problem Tree Diagram Health Center
- PROBLEM ANALYSIS. Root Cause Analysis Tree Diagram | Small ...
- Tree Diagram Pdf Of Health Management
- Fishbone diagram - HAN project | Relations diagram - Health care ...
- Fishbone Diagram Health Problem
- Fishbone diagram - HAN project | TQM Diagram — Professional ...
- Diagram Of Health Management
- Fishbone Diagrams | Fishbone Diagram | Fault Tree Analysis ...
- Social Control Tree Diagram
- Health Planning Diagram