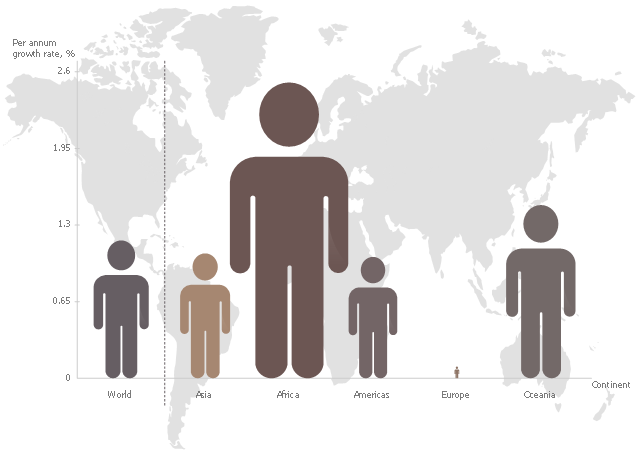
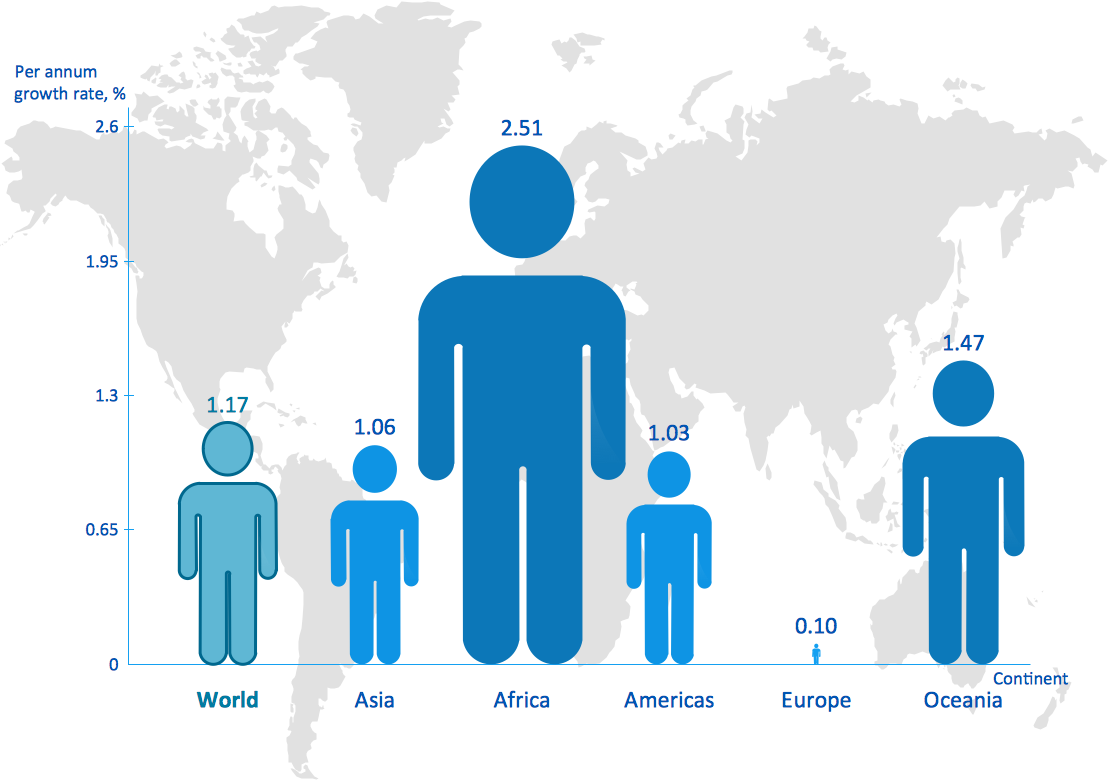
This pictorial chart sample shows the population growth by continent in 2010-2013.
"Population growth' refers to the growth in human populations. Global population growth is around 80 million annually, or 1.2% p.a. The global population has grown from 1 billion in 1800 to 7 billion in 2012. It is expected to keep growing to reach 11 billion by the end of the century. Most of the growth occurs in the nations with the most poverty, showing the direct link between high population growth and low standards of living. The nations with high standards of living generally have low or zero rates of population growth. Australia's population growth is around 400,000 annually, or 1.8% p.a., which is nearly double the global average. It is caused mainly by very high immigration of around 200,000 p.a., the highest immigration rate in the world. Australia remains the only nation in the world with both high population growth and high standards of living." [Population growth. Wikipedia]
The image chart example "Population growth by continent, 2010 - 2013" was created using the ConceptDraw PRO diagramming and vector drawing software extended with the Basic Picture Graphs solution from the Graphs and Charts area of ConceptDraw Solution Park.
"Population growth' refers to the growth in human populations. Global population growth is around 80 million annually, or 1.2% p.a. The global population has grown from 1 billion in 1800 to 7 billion in 2012. It is expected to keep growing to reach 11 billion by the end of the century. Most of the growth occurs in the nations with the most poverty, showing the direct link between high population growth and low standards of living. The nations with high standards of living generally have low or zero rates of population growth. Australia's population growth is around 400,000 annually, or 1.8% p.a., which is nearly double the global average. It is caused mainly by very high immigration of around 200,000 p.a., the highest immigration rate in the world. Australia remains the only nation in the world with both high population growth and high standards of living." [Population growth. Wikipedia]
The image chart example "Population growth by continent, 2010 - 2013" was created using the ConceptDraw PRO diagramming and vector drawing software extended with the Basic Picture Graphs solution from the Graphs and Charts area of ConceptDraw Solution Park.
Image chart
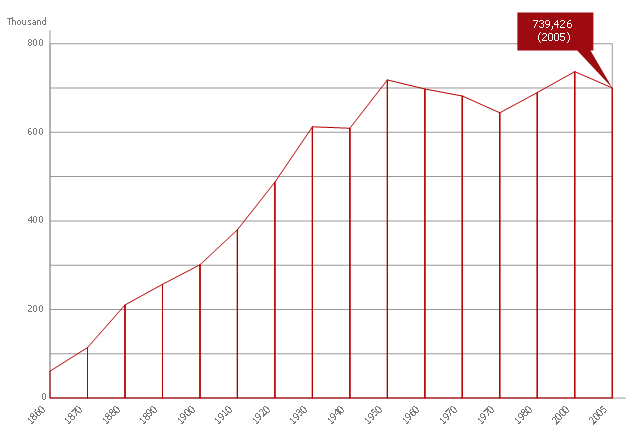
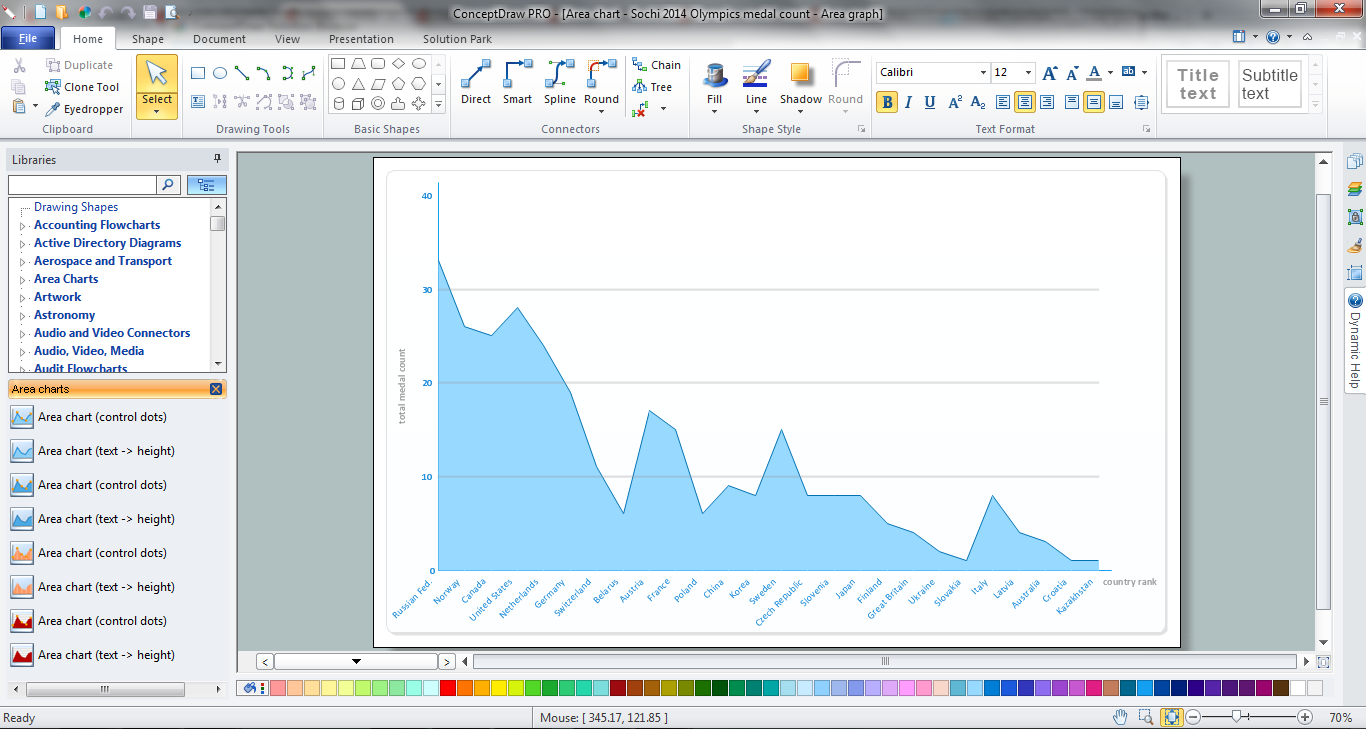
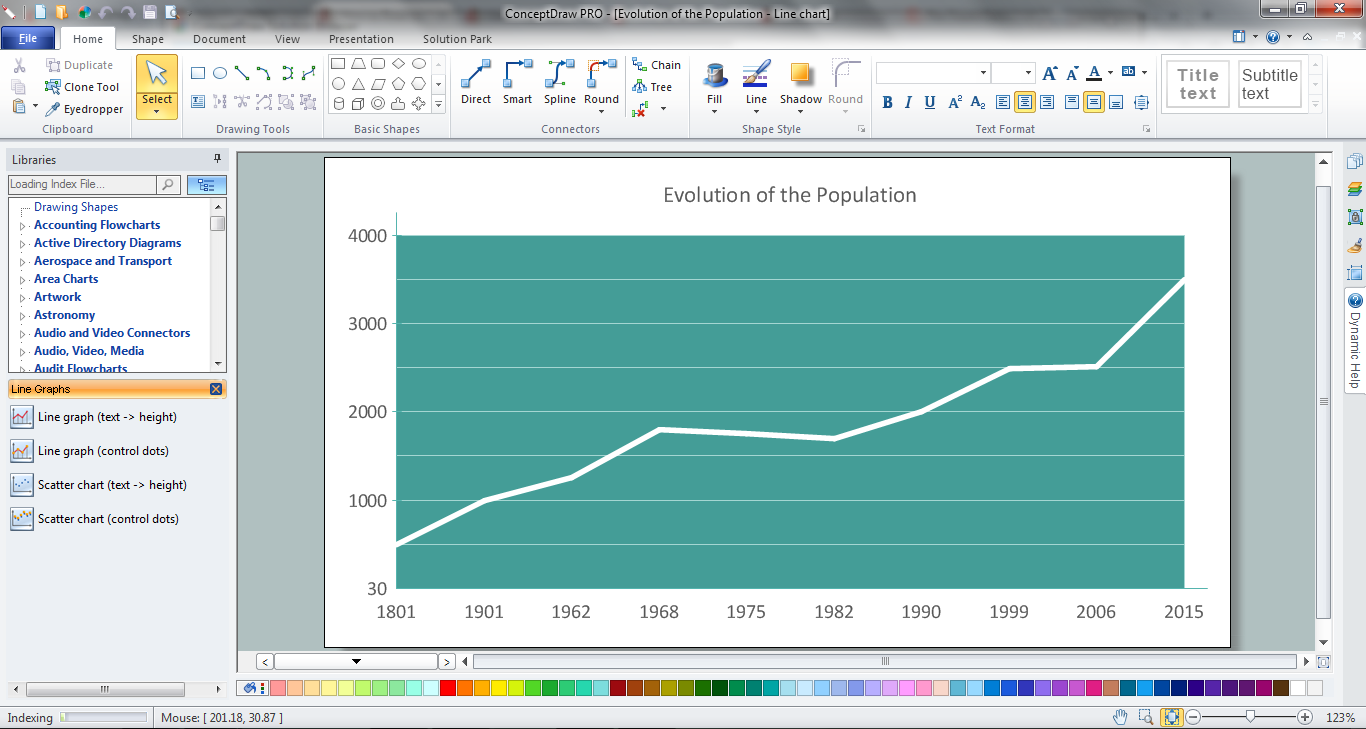
This area chart sample shows the population growth of San Francisco, California from 1850-2005. It was redesigned from the Wikimedia Commons file: San Francisco CA Population Growth.svg. [commons.wikimedia.org/ wiki/ File:San_ Francisco_ CA_ Population_ Growth.svg]
"The San Francisco Bay Area, commonly known as the Bay Area, is a populated region that surrounds the San Francisco and San Pablo estuaries in Northern California, United States. The region encompasses the major cities and metropolitan areas of San Francisco, Oakland, and San Jose, along with smaller urban and rural areas. The Bay Area's nine counties are Alameda, Contra Costa, Marin, Napa, San Francisco, San Mateo, Santa Clara, Solano, and Sonoma. Home to approximately 7.44 million people, the nine-county Bay Area contains many cities, towns, airports, and associated regional, state, and national parks, connected by a network of roads, highways, railroads, bridges, tunnels and commuter rail. The combined urban area of San Francisco and San Jose is the second largest in California (after the Greater Los Angeles area), the fifth largest in the United States, and the 56th largest urban area in the world." [San Francisco Bay Area. Wikipedia]
The area graph example "San Francisco CA Population Growth" was created using the ConceptDraw PRO diagramming and vector drawing software extended with the Area Charts solution from the Graphs and Charts area of ConceptDraw Solution Park.
"The San Francisco Bay Area, commonly known as the Bay Area, is a populated region that surrounds the San Francisco and San Pablo estuaries in Northern California, United States. The region encompasses the major cities and metropolitan areas of San Francisco, Oakland, and San Jose, along with smaller urban and rural areas. The Bay Area's nine counties are Alameda, Contra Costa, Marin, Napa, San Francisco, San Mateo, Santa Clara, Solano, and Sonoma. Home to approximately 7.44 million people, the nine-county Bay Area contains many cities, towns, airports, and associated regional, state, and national parks, connected by a network of roads, highways, railroads, bridges, tunnels and commuter rail. The combined urban area of San Francisco and San Jose is the second largest in California (after the Greater Los Angeles area), the fifth largest in the United States, and the 56th largest urban area in the world." [San Francisco Bay Area. Wikipedia]
The area graph example "San Francisco CA Population Growth" was created using the ConceptDraw PRO diagramming and vector drawing software extended with the Area Charts solution from the Graphs and Charts area of ConceptDraw Solution Park.
Area chart
Basic Diagramming

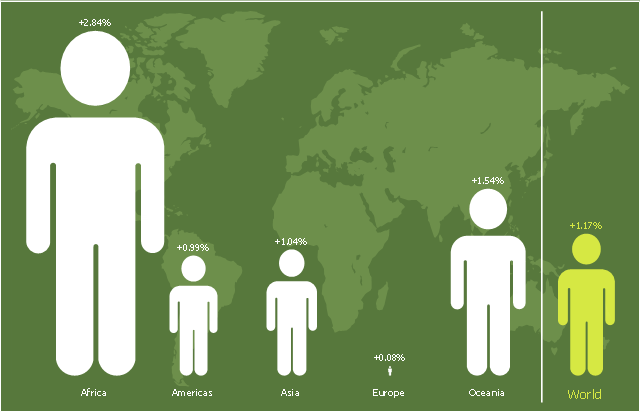
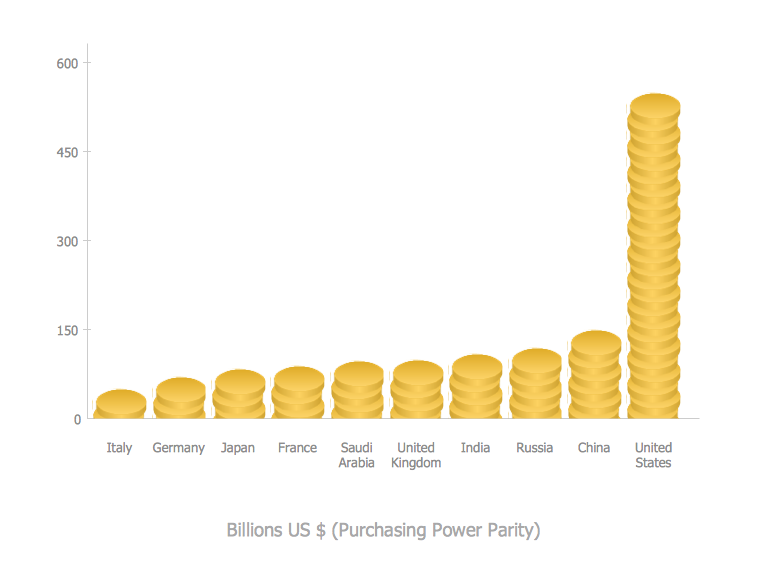
This picture bar graph sample shows regional population growth from 2010 to 2016. It was designed using data from the Wikipedia article List of continents by population.
[en.wikipedia.org/ wiki/ List_ of_ continents_ by_ population]
"Population geography is a division of human geography. It is the study of the ways in which spatial variations in the distribution, composition, migration, and growth of populations are related to the nature of places. Population geography involves demography in a geographical perspective. It focuses on the characteristics of population distributions that change in a spatial context." [Population geography. Wikipedia]
The pictorial chart example "Regional population growth from 2010 to 2016" was created using the ConceptDraw PRO diagramming and vector drawing software extended with the Picture Graphs solution from the Graphs and Charts area of ConceptDraw Solution Park.
[en.wikipedia.org/ wiki/ List_ of_ continents_ by_ population]
"Population geography is a division of human geography. It is the study of the ways in which spatial variations in the distribution, composition, migration, and growth of populations are related to the nature of places. Population geography involves demography in a geographical perspective. It focuses on the characteristics of population distributions that change in a spatial context." [Population geography. Wikipedia]
The pictorial chart example "Regional population growth from 2010 to 2016" was created using the ConceptDraw PRO diagramming and vector drawing software extended with the Picture Graphs solution from the Graphs and Charts area of ConceptDraw Solution Park.
Image chart
Pictures of Graphs
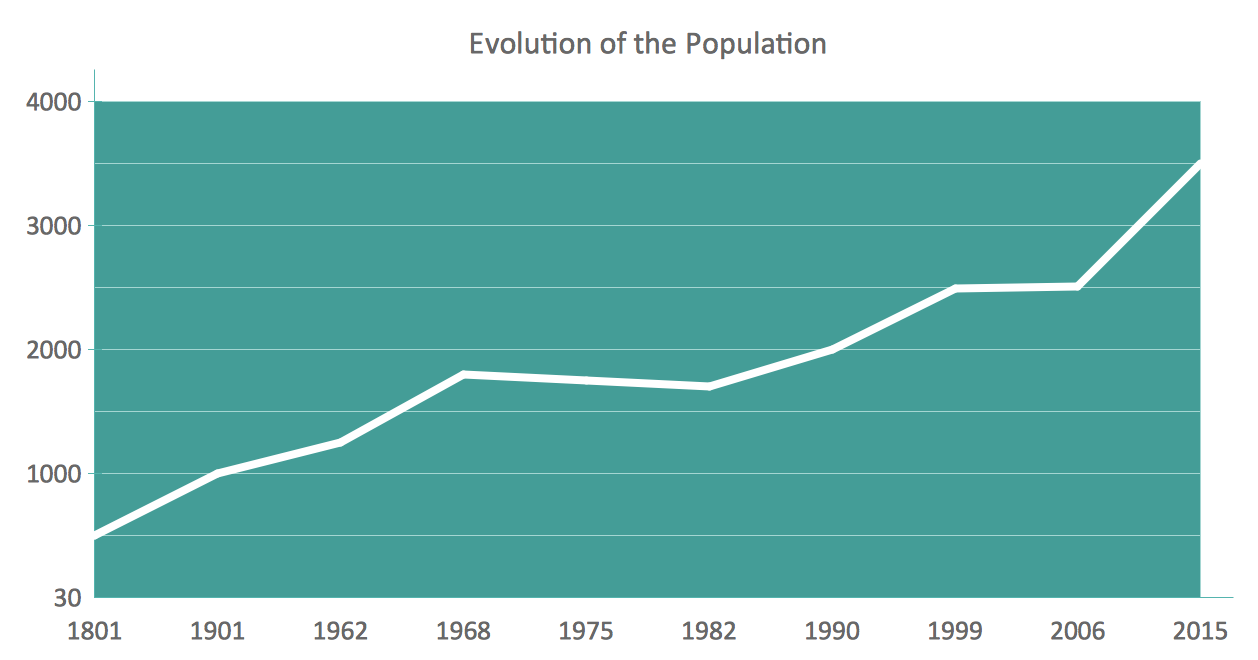
Area Chart
Line Chart Examples
Picture Graph
Line Graph
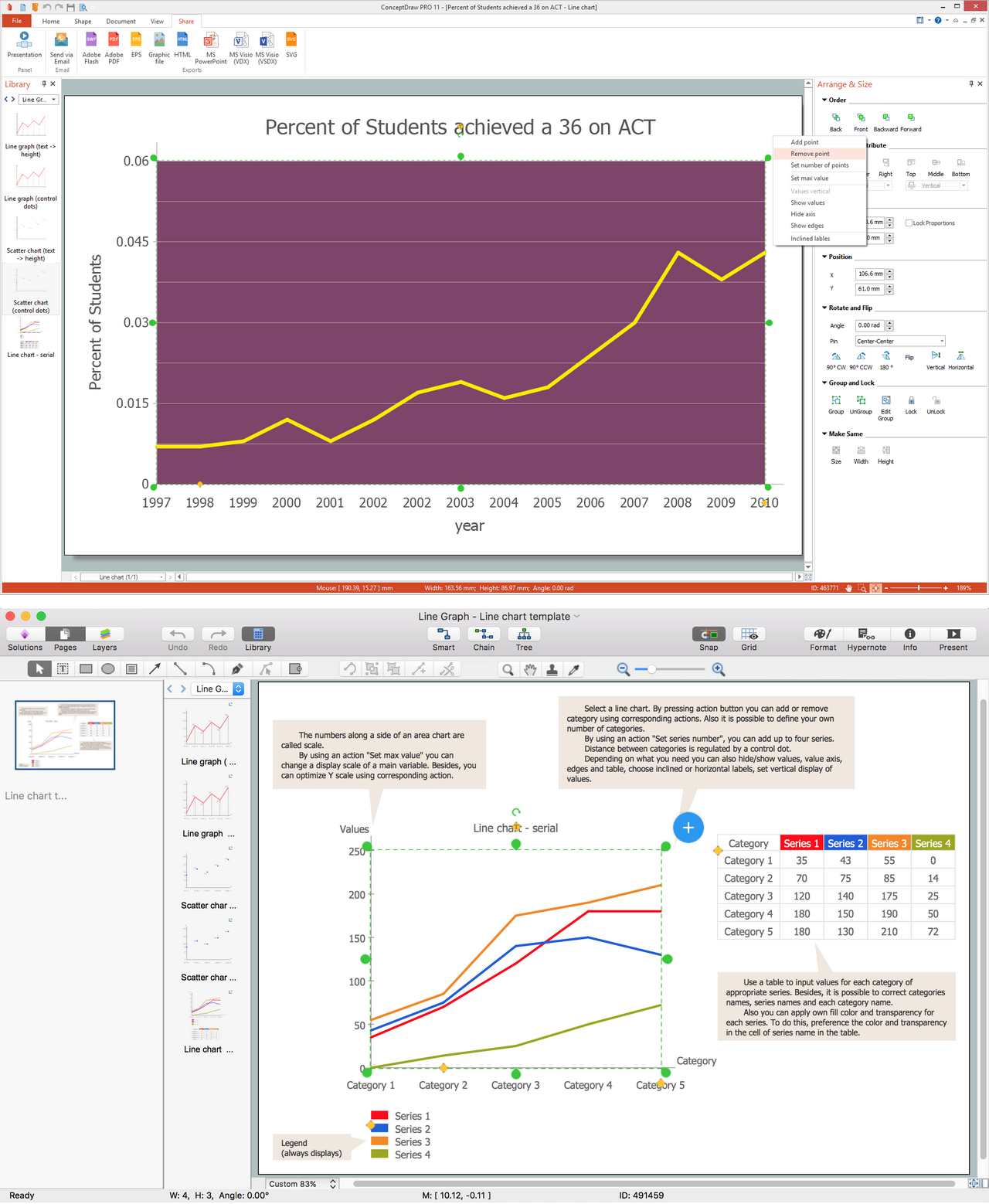
 Basic Area Charts
Basic Area Charts
This solution extends the capabilities of ConceptDraw DIAGRAM (or later) with templates, samples and a library of vector stencils for drawing Area Charts (area graphs) that visualize changes in values by filling in the area beneath the line connecting data points.
How To Create Floor Plans

How to Draw a Line Graph
Infographic Maker

What Is a Picture Graph?

Create Graphs and Charts

- Solution For Population Explosion In Drawing
- Population Explosion Flow Chart
- What Is Population Explosion With The Help Of Graph
- Population Explosion Drawing Img
- Basic Diagramming | Regional population growth from 2010 to 2016 ...
- Drawing Of Population Explosion
- Population growth by continent | Geo Map - Africa - Madagascar ...
- Pie Chart On Population Explosion
- San Francisco CA Population Growth | Basic Diagramming ...
- Population Explosion Drawing
- Population growth by continent | San Francisco CA Population ...
- Regional population growth from 2010 to 2016 | Basic Diagramming ...
- Population growth by continent | Regional population growth from ...
- San Francisco CA population growth | Population growth by ...
- Flow Population Explosion
- Regional population growth from 2010 to 2016 | Pictures of Graphs ...
- Populatiin Explosion In Flow Chart
- Populations Explosion Drawing
- Population Growth Pie Chart Image
- Line Chart Examples | San Francisco population history | San ...